

In cloud computing, “Serverless” is the paradigm where you can execute code without needing to maintain your own server, and you only pay for what you use.
It’s worth mentioning that serverless does indeed run on servers under the hood, but cloud providers handle their operation fully and make it scalable and reliable.
Serverless has been around for over a decade, and most cloud computing providers have leveraged it to the point of widespread adoption. Its benefits have become well-known and proven. Books have been written about microservices and the event-driven architecture that serverless encourages developers to use.
In this post, we’ll explore the serverless conundrum: How the opposing benefits and technical difficulties involved make it hard to decide whether serverless is right for a project.
For some, serverless is the key to cost-efficient and fast-paced feature release. For others, it can become a painful decision when migrating, and especially afterwards, when it’s time to monitor a large system or to switch providers.
Luckily, today we see different development patterns, services, and other solutions bubbling up for most of the technical challenges your team may face.
The good, the bad, and the ugly of going Serverless
Some teams have invested in porting vast amounts of code from an existing monolith application into a wider array of isolated services. New systems, on the other hand, can be designed with an async event-driven architecture from day one, building scalable microservices from scratch.
The good
The function granularity of the serverless paradigm brings sound benefits:
- Improved scalability (preventing performance issues under intense load)
- High availability (cloud-backed distributed, secure, and fault-tolerant infrastructure)
- Faster deployment (more atomic deployments)
- Server maintenance is eliminated completely (freeing the team to focus on development instead of the operations burden)
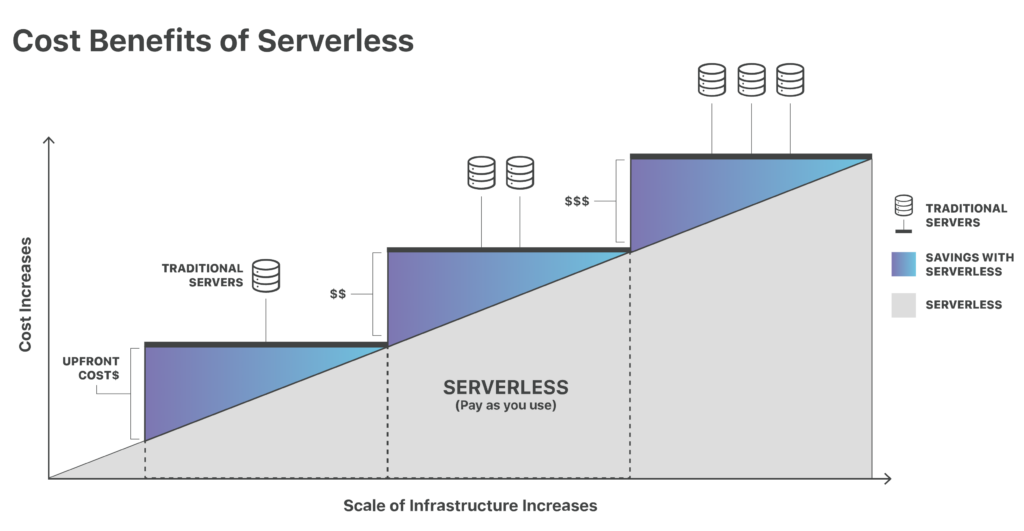
- Server costs are substantially lower compared to traditional servers (it’s worth mentioning that switching to a pay-as-you-use system makes sense when we don’t need to run a process 24/7; otherwise, it would make sense to stick to a traditional server)
The bad
Here are some of the cumbersome problems that teams might face with serverless:
- Mindset shift for most developers (async event-driven programming is not as straight-forward, and there’s a learning curve to go through)
- Deployment Orchestration (especially when releasing multiple microservices at once, which might involve coordinating multiple different teams)
- Error handling and retries (async error handling has some nuances not found in a traditional request-response architecture model, especially when chaining functions)
Now, let’s dive into some of the most critical serverless issues and how to prevent them:
The ugly
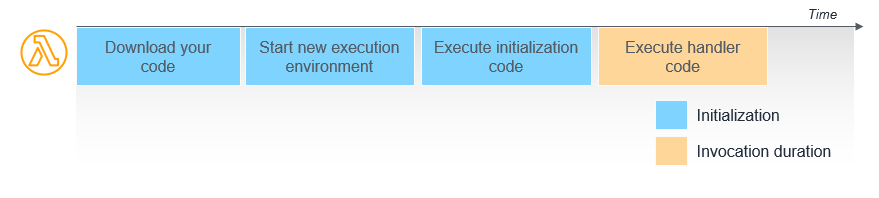
Cold starts
Cloud providers need an instance of the function to be spun up in order to execute the code. When a function is idle or inactive for some time, that instance is dropped as part of the cloud provider’s efficient resource management that makes serverless scalable. When that function is invoked again, it needs to be re-instantiated, adding latency.
The most straightforward workaround is to keep functions warm (or available/deployed) by hitting them at regular intervals, preventing the cloud provider from shutting down the instance. But it’s not an optimal solution, and it can get costly.
It all boils down to the true nature of serverless: The application must be architected so that functions are small and concise and have a single responsibility and little code, with as few dependencies as possible. Cold start times are somewhat proportional to the amount of memory the function uses and the amount of code it contains.
Another possible optimization is to use Provisioned Concurrency, where you estimate the number of invocations a function will have, so warm instances will be readily available for a faster invocation.
Logging and monitoring
Serverless functions are meant to be stateless, making it harder to debug in production using anything but logs. Also, while the serverless paradigm is still a novelty for a development team, getting the necessary information or proper performance data when facing an outage can make a huge difference.
To monitor the efficiency and adequate behavior of a serverless system, multiple factors come into play:
– Metrics like average time per invocation, invocations per minute, amount of errored invocations, and service-quota throttles are all important indicators.
– Plain old log lines with a timestamp to show a record of the events happening at runtime and help identify failures or errors, hopefully containing some context for debugging.
– Alerts or automatic monitoring is a must-have for receiving notifications when hitting specific thresholds on one or more of the previously mentioned metrics. For example, if we see a spike in 4xx or 5xx errors, or in execution time, then something’s probably gone wrong.
– Using graphics to visualize metrics and how they evolve over time makes it easier and quicker to spot patterns, network problems or other operational issues when there’s increased concurrency, or after releasing a new product feature.
– When chaining multiple functions, following a request end-to-end through the different microservices might be the key to successfully investigating a bottleneck or other issues.
There’s still a lot of room for improvement in the serverless observability department. Still, there are solutions that can help gain insight into how functions perform, finding and alerting about any bugs and runtime errors, and analyzing how much they cost to operate. Some examples include cloud-native services like AWS Cloudwatch and AWS X-Ray, or other tools like Datadog, Lightrun, and Dashbird.io.
Cloud vendor lock-in
Depending on the complexity of the system, there may or may not be a way to use cloud services in a truly vendor-agnostic way. Implementation under a vendor ecosystem can easily become a trap, preventing you from switching to another cloud provider.
Some important factors to consider are:
- Language support: Choose your runtime wisely. For example: C# is not supported in GCP, but it is on AWS; Go is not supported in Azure, but Javascript/NodeJS and Python are supported across the board.
- Architecture Pattern: Good architecture makes it easier to migrate functions simply by adding a level of abstraction, ideally leaving function code unchanged. This requires only plugging in new adapters and changing configuration, so porting to a new vendor is not as costly.
- Identity and Access Management: When a system requires a complex scheme of permissions and policies, this could add a fair amount of work when migrating to another cloud vendor. It may not only be the code that needs to be ported.
A good approach is to prevent vendor lock-in at the architecture level. But when designing a system to use cloud services, it’s inevitable to have code be coupled in some way.
Most of the code should still be developed and tested as usual, with unit tests and any other tools we normally use. The “coupled serverless” part should be just the interface to our logic, and therefore, can only be tested when its integration with user requests or other triggers changes. The idea here is to concentrate on keeping costs low when switching to a different cloud vendor when needed.
We can also use tools like the Serverless Framework (serverless.com), which can help abstract the deployment of code and infrastructure provisioning.
Wait, what about containerization?
Both serverless and containers have been around for quite some time now, helping teams move away from traditional bare-metal operations or on-premises infrastructure. They are not mutually exclusive and can co-exist, and both have their place as architecture components of a system.
An advantage of serverless functions is that they can scale up or down out-of-the-box. For containers, in turn, you need Kubernetes or other tools to orchestrate based on different criteria.
A key benefit of containers is that vendor lock-in is less of a concern. They can usually be deployed neutrally under any cloud vendor with minimum friction. Containers can also come in handy when running applications written in languages that are not available in the current serverless services offering.
Containers can be easily run in most environments, even the developer’s computer. Serverless functions, in turn, are hard to run locally while developing, though some tools to emulate the cloud environment do exist.
As a rule of thumb, serverless functions are often best for short-lived cloud-native processes. Containers, on the other hand, work best for long-running processes, multiple services that are too tightly coupled to split, or stateful applications with multiple responsibilities or that need to run processing jobs 24/7.
Conclusion
So, serverless… Is it worth it? Absolutely! It has shown that it is a great operational or execution model and it is here to stay. Gone are the days of keeping servers up-to-date, applying security patches, or worrying about how the server will scale under a heavy load.
Keep in mind, though, that these benefits come at a price. There’s a learning curve to go through to use serverless effectively, and the implementation details will depend on the problem we are trying to solve.
Teams must grow by learning from past mistakes and from other teams’ experiences, embrace the challenges of cultivating an async event-driven microservices architecture, and then harvest the benefits of an affordable, flexible, and almost invisible infrastructure that serverless is.